Finetuning Qwen3-4B avec Unsloth
Introduction
En creusant avec curiosité dans la curiosité, je me suis retrouvé face à Unsloth pendant ma veille il y a environ 6 mois, mais à ce moment là, je n'avais pas encore l'hardware nécessaire pour vraiment le faire tourner en local et je ne suis pas très fan de Google Collab (bien que Google Collab peut être super interessant si nous n'avons pas de TPU/GPU sous la main).
Bon, on se fait un petit notebook
Comme ça c'est plus facile, rapide, modulable, et on peut bidouiller tranquillement.
Extrêmement important, j'installe mon petit thème pastel préféré au monde. (Catppuccin)
On teste le modèle avant
Okay alors déjà, on va faire tourner Qwen3-4B avec Unsloth et voir un peu ce que le modèle en dit et ce qu'il connaît. Mon but, là tout de suite, c'est de voir s'il a des connaissances sur Gleam. Donc on va regarder la documentation.
from unsloth import FastLanguageModel
import torch
import os
from transformers import TextStreamer
MODEL_PATH = "unsloth/Qwen3-4B"
MAX_SEQ_LENGTH = 1024
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = MODEL_PATH,
max_seq_length = MAX_SEQ_LENGTH,
load_in_4bit = True,
fast_inference = False,
)
FastLanguageModel.for_inference(model)
Donc là, on va simplement charger le modèle en RAM pour pouvoir lui parler tranquillement
def chat():
history = []
print("Tapez 'exit' pour arrêter.")
while True:
user_input = input("\n[Vous] > ")
if user_input.lower() in ["exit", "quit", "q"]:
break
history.append(
{"role": "user", "content": user_input}
)
tokenized_data = tokenizer.apply_chat_template(
history,
tokenize = True,
add_generation_prompt = True,
return_tensors = "pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
print("\n[Assistant] > ", end="", flush=True)
outputs = model.generate(
input_ids = tokenized_data,
streamer = text_streamer,
max_new_tokens = 512,
use_cache = True,
temperature = 0.7,
do_sample = True,
pad_token_id = tokenizer.pad_token_id,
)
response = tokenizer.decode(outputs[0][len(tokenized_data[0]):], skip_special_tokens=True)
history.append({"role": "assistant", "content": response})
chat()
Et je reprends ce petit bout de code que j'avais fait il y a un moment pour du llama-cpp, mais en l'adaptant un peu pour unsloth.
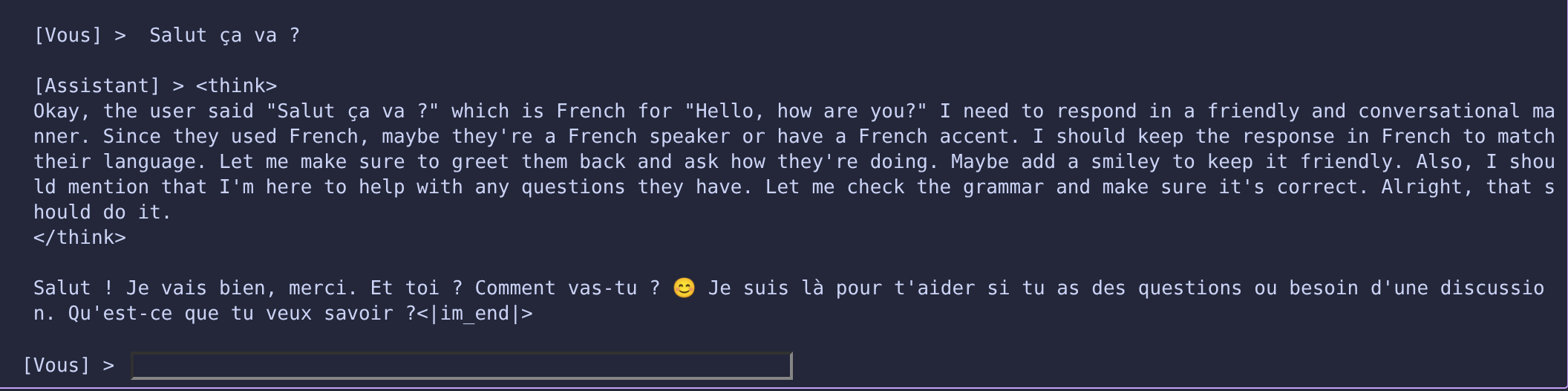
Bon, ok déjà on remarque les
<think>et les</think>dans la réponse, c'est pas mal, c'est un modèle qui "réfléchit" avant de répondre, mais bon, c'est pas encore parfait.
Donc, parlons-lui un peu de Gleam et demandons-lui de générer un peu de code
"Donne un exemple de code en Gleam pour faire un 'hello world'"Et on remarque direct qu'il ne réfléchit pas si mal, c'est même plutôt ok !
Okay, the user is asking for an example of code in Gleam to print "hello world".
Let me recall how Gleam works. Gleam is a functional programming language that's similar to Elixir, but with a focus on performance.
It uses a compile-to-WebAssembly approach, so the code would be written in a way that's compatible with that.
C'est quand même assez correct, similaire à Elixir, il sait que c'est un langage fonctionnel...
Mais bordel au niveau du code ressorti, ça chie fort fort dans le pantalon.
Réponse de Qwen3-4B
module HelloWorld
@main
fn main() {
IO.println("hello world")
}
- Explication :
module HelloWorld: Définit le nom du module.@main: Marque la fonction comme point d'entrée du programme.fn main() { ... }: Définit la fonction principale.IO.println("hello world"): Affiche "hello world" dans la console.
Donc là, on voit clairement qu'il ne sait pas vraiment ce qu'il dit ni ce qu'il fait. Pour qu'il en sache plus, on a deux choix : injecter dans le prompt des données sur Gleam, mais du coup ça consommerait potentiellement plus de tokens et prendrait peut-être un peu plus de temps, ou spécialiser le modèle pour le Gleam en effectuant un LoRA avec Unsloth (Low Rank Adapter).
Dans mon cas, je veux faire du LoRA, mais j'ai pas l'hardware donc, ça sera du QLoRA, du LoRA en 4-bit.
Le vrai but
Faire en sorte que le modèle soit vraiment performant pour de la modification et la création de code en Gleam.
Pourquoi ? Ça paraît être un usage bête, mais étant un langage "naissant", le Gleam n'a pas énormément d'informations disponibles en ligne, donc les petits modèles ont souvent très peu de connaissances en Gleam. On verra donc un avant/après très clair.
On se fait un dataset
Comme on l'a vu précédemment, le modèle réfléchit, donc il va falloir prendre ça en compte pour générer le dataset.
Je vais privilégier le XML pour la génération de mon dataset, parce que je trouve ça plus lisible que le JSON et qu'on peut faire des sauts de lignes facilement, nan le XML j'aime trop ça.
Et donc si je veux spécialiser vraiment le modèle, je vais imposer une structure claire :
<entry>
<user></user>
<think></think>
<code></code>
<explanation></explanation>
</entry>
On train
Pour ce qui va suivre, je vais me baser en grande partie sur cet article : https://medium.com/@matteo28/qlora-fine-tuning-with-unsloth-a-complete-guide-8652c9c7edb3
Okay, donc on va configurer un adapter LoRA sur notre modèle qui est complètement gelé (frozen) ! (En gros, le finetuning avec QLoRA c'est qu'on va rajouter des poids par-dessus notre modèle, et on ne va entraîner que ces poids-là, ce qui fait qu'on consomme beaucoup moins de VRAM tout en gardant la puissance de base du modèle).
LORA_R = 16 # Rank of LoRA matrices
LORA_ALPHA = 16 # Scaling factor
TARGET_MODULES = [
"q_proj", "k_proj", "v_proj", "o_proj", # Attention
"gate_proj", "up_proj", "down_proj", # MLP
]
model = FastLanguageModel.get_peft_model(
model,
r=LORA_R,
target_modules=TARGET_MODULES,
lora_alpha=LORA_ALPHA,
lora_dropout=0, # 0 is optimized for speed
bias="none",
use_gradient_checkpointing="unsloth", # 30% less VRAM
random_state=3407,
)
Et dans notre cas, on peut train Trainable: 33,030,144 (1.2996%).
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in model.parameters())
print(f"Trainable: {trainable_params:,} ({100 * trainable_params / all_params:.4f}%)")
Et donc je vais charger le dataset avec notre format précédent.
return {
"user": example["user"],
"response": f"<think>\n{example['think']}\n</think>\n\n{example['code']}\n\n<explanation>\n{example['explanation']}\n</explanation>"
}
# Le but ici c'est de formater la réponse du dataset de façon efficiente
Okay et donc on a plein de données générées avec Gemini Flash (J'ai Google AI Pro avec mon statut d'étudiant, je me mets bien).
On lance l'entraînement
Maintenant qu'on a tout, on configure le SFTTrainer qui va s'occuper de coordonner l'entraînement.
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = gleam_ds, # On utilise le dataset brut
formatting_func = formatting_prompts_func,
max_seq_length = 1024,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 1,
gradient_accumulation_steps = 8,
gradient_checkpointing = True,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "paged_adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
En gros, le SFTTrainer fait le pont entre le modèle, le tokenizer et nos données formatées. Les TrainingArguments permettent de définir comment le modèle apprend (vitesse, mémoire, nombre d'itérations). Ici, on optimise à fond pour que ça tourne même sur une config modeste (un peu éclatée) grâce au QLoRA et au checkpointing.
C'est entrainé, testons :3
Okay, maintenant le plus dur est fait, testons ! Par défaut, je dirais qu'il faudrait préparer un vrai benchmark pour ce cas d'usage spécifique et comparer avec d'autres modèles pour avoir un ordre d'idée de ses performances, mais ça fera l'affaire pour un autre article !
Donc on va tester ce petit modèle avec une petite question sur Gleam : "Donne un exemple de code en Gleam pour faire un 'hello world'"
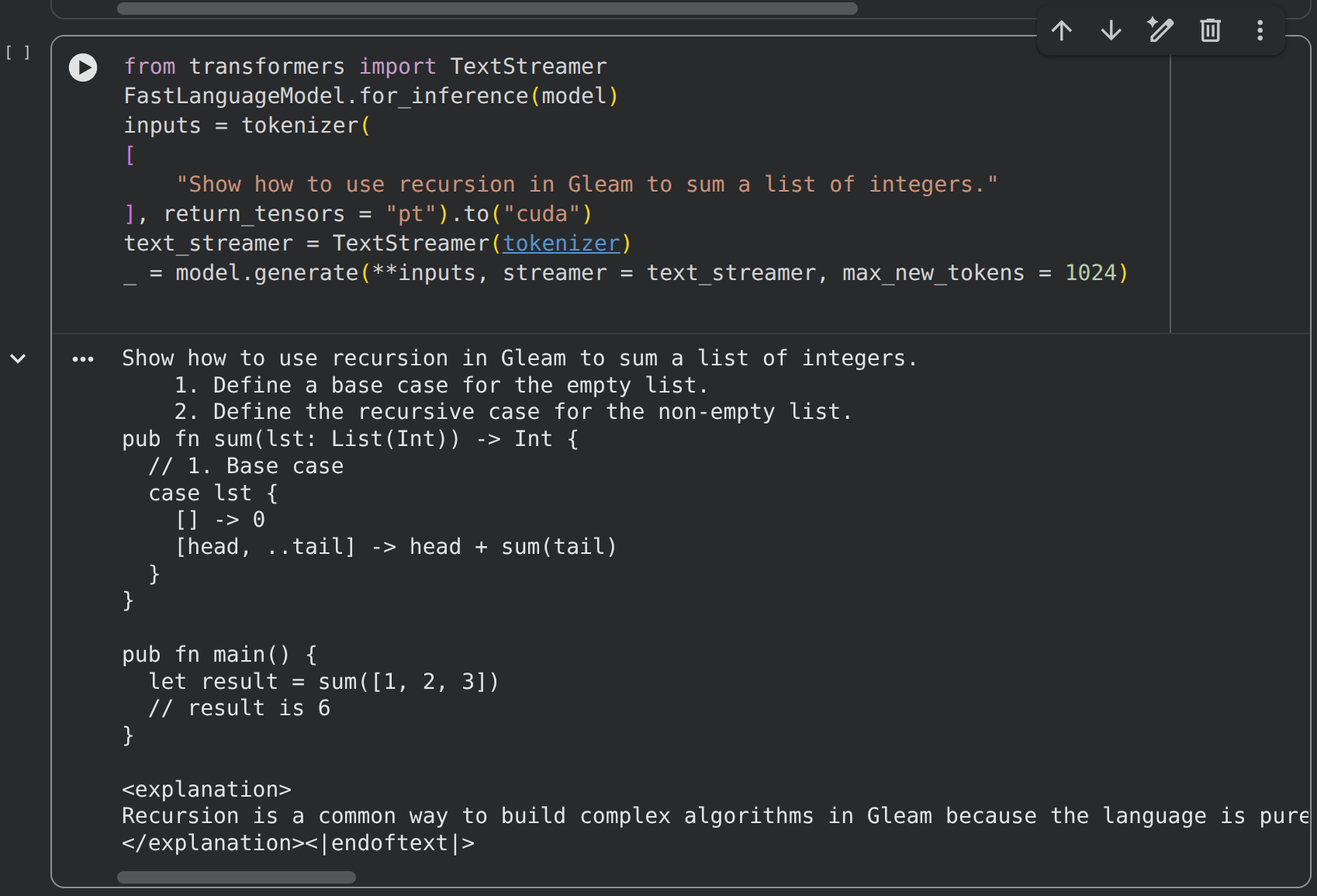
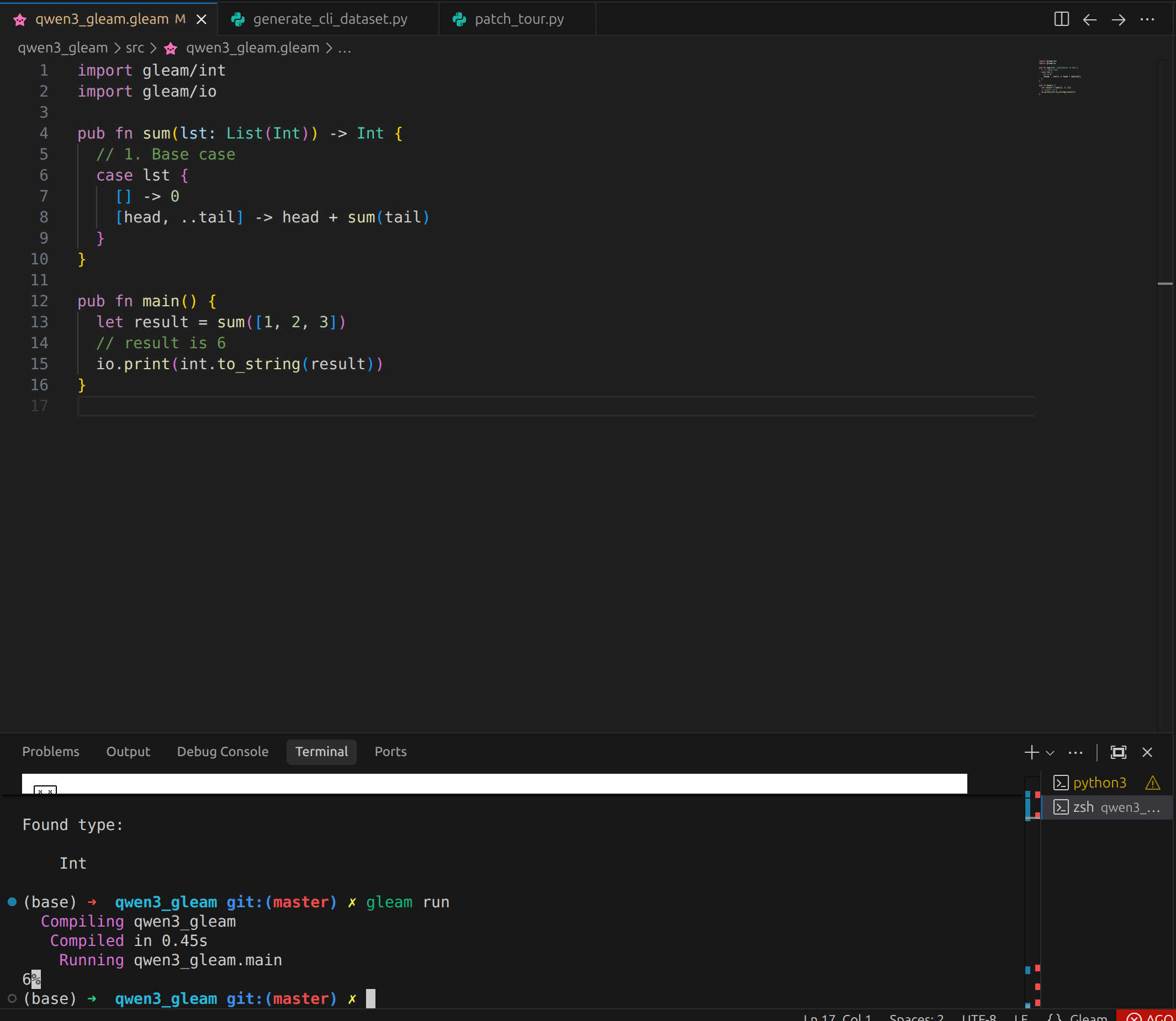
Et le code marche !!!!! ON A DU CODE QUI MARCHE !!!!!!!! Je suis très très content. J'adore ça. Quel bonheur.
(J'ai juste ajouté un log pour voir s'il marchait, le code, et hop)
Notes : il est 14:12, je viens de voir que Qwen venait de sortir Qwen3.5 en 4B (en gros, ils ont sorti les 3.5 en version small). Bon, j'ai un peu le seum, j'aurais dû fine-tuner celui-là, mais bon je pense que j'en ferai autre chose.
Conclusion
J'ai fait un test, ça a marché, je suis content, mais pour en être sûr il faudrait tester en pratique et avec un benchmark. Ça fera l'affaire d'une prochaine note :)